
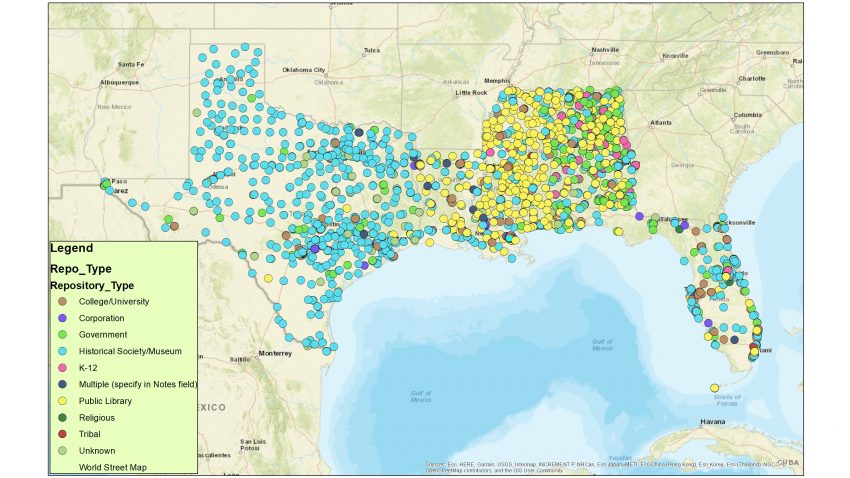
Archives located in the Gulf South
In recent years, there’s been growing awareness within the United States cultural heritage community about exposure to climate change. Many emerging communities of concerned cultural heritage professionals have emerged. There is now a Coalition of Museums for Climate Justice, the American Library Association Sustainability Roundtable, and ProjectARCC (Archivists Responding to Climate Change). Climate change is showing up at conferences and journals in the field.
One of the major challenges in assessing the risk of climate change to cultural heritage is that data on cultural heritage is inconsistent. How can you predict how many museums, libraries, or archives will be exposured to climate change without adequate data on how many institutions exist in a given vulnerable location? There is a lot of great data on museums thanks to the Museum Universe Data File. There is a semi-representative directory of American libraries (but it leaves out school libraries). But as an archivist working on climate change issues, I was pretty dismayed to discover a few years ago that there really isn’t a comprehensive data set of archives in the United States.
Last year, my research collaborator Ben Goldman (Penn State University) and I received a Society of American Archivists (SAA) Foundation grant to attempt to compile the first comprehensive data set of all US archives. The roots of this project began with an article we co-authored with geospatial experts from Penn State, in which we took a very limited data set of around 1,200 archives (furnished by OCLC’s ArchiveGrid) and examined their exposure to climate change risks, like sea-level rise, storm surge, and changes in temperature/humidity. However, we knew if there was ever going to be a comprehensive risk assessment of US archives, someone had to bring together a comprehensive data set of how many US archives exist and where they are located. This is what we set out to do with our SAA Foundation grant.
Over the course of the grant, we worked with a fantastic assistant, Whitney Ray, who did an incredible amount of heavy lifting with contacting over 150 archival organizations for any data they had. Essentially, we reached out to anyone we thought may have maintained lists of archives in their region or area of interest. What we received was over 30,000 raw data points! The data came to us in every way you can imagine – from very tidy spreadsheets to webpages with broken links to PDFs of archives. You can read much more about our workflow and process on our RepoData project blog.
We’ve now made data available for 30 states plus Washington DC on our public GitHub repository. We plan to work through the remainder of the states through 2018. While we originally created this data because we know it’s critical for future climate assessment work, we know there will be a lot of potential reuse for it – and we’re excited to see how people use it!