
One of my research areas is examining the role of recordkeeping and documentation in environmental regulations. A research tactic I frequently use is to sift through hundreds of PDFs at once. Large numbers of PDFs are posted on many environmental regulatory websites, but there isn’t a lot of information about what’s in them or how big they are, or where the juicy stuff is. If this sounds daunting – well, it is! But I’ve come up with a few tricks to help me sort out what is useful and what isn’t.
Step 1: Download
The first thing is figuring out how to download a zillion PDFs at once. For this, I recommend getting a bulk downloader add-on for your browser (here is an example). This will scan through every URL on a page that ends with .pdf, which indicates that the URL is likely a downloadable PDF. A bulk downloader prevents the need from clicking on every single link, which can be a lot when you’re on a page with dozens of PDFs like this one from the Mine Safety and Health Administration.
Step 2: Text Recognition
Once you download all the files you want, I like to place them into a dedicated folder. This is because even though theoretically most government agency PDFs should have optical character recognition (OCR), the actual practice is very inconsistent. OCRed text is critical for PDF searching because it allows you to do a keyword search within a single file or across multiple files at once. Currently, there is not widely-available OCR functionality for cursive or handwriting, just typeface.
Adobe Acrobat has a useful function (under Tools > Text Recognition > In Multiple Files) where you can run the OCR function across everything in a specific folder. This can take a while, but at least there is a progress bar that’ll show you how long it takes – which could be a while, considering that many government environmental regulation records can be a hundred pages for each file. Using the Adobe Acrobat tool also allows you to keep or modify original file names. I like to downsample the files to 600 dpi – it takes longer than the lower dpi measures, but I think it enables better keyword searches later on.
Step 3: Dig into the PDF files!
There is a free software program called PDF-XChange Viewer, which you can use to do keyword searches over large amounts of PDFs. You can also run a similar search within Adobe Acrobat, but I find that the searching takes far longer and the results are presented less tidily than with PDF-XChange Viewer. Supposedly you can also run batch OCR with this program, but I haven’t tried it.
The example demonstrates how I wanted to find PDFs from coal mine inspection safety reports that mention the word “map.” The results show me that of the dozens of documents I searched in my dedicated folder, there were 187 hits for the word “map” across 14 of the documents. I can get an idea from the left-hand preview pane what the keyword is like in context, and then click on that to see the actual PDF in the right-hand window.
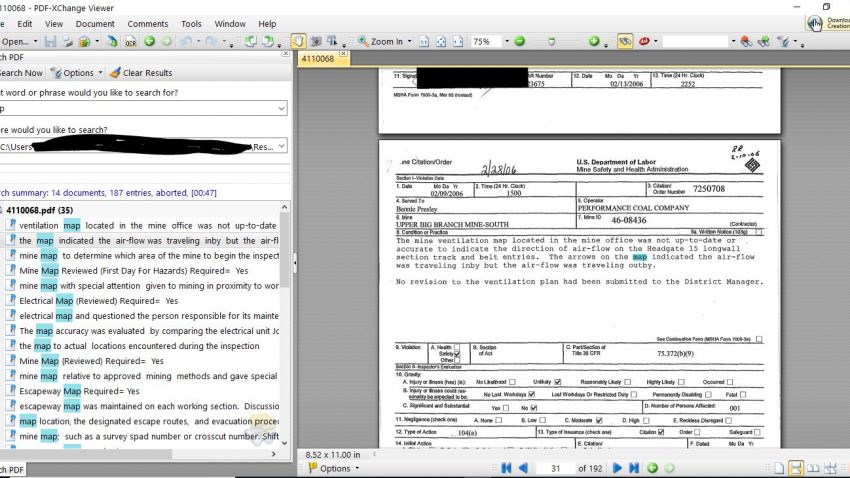
This step helps me pull out the PDFs that I need to analyze more deeply, thus saving me the headache of opening up every single PDF in case it might have something of interest.