
By Eira Tansey, Digital Archivist/Records Manager
A constant challenge for digital archivists is identifying potentially sensitive material within born-digital archives. This content may be information that fits a known pattern (for example, a 3-2-4 number that likely indicates the presence of a social security number), or sensitive keywords that indicate the presence of a larger body of sensitive information (for example, the keywords “evaluation” and “candidate” in close proximity to each other may indicate the presence of an evaluation form for a possible job applicant).
Digital archivists use a number of tools to screen for potentially sensitive information. When this information is found, depending on the type of information, institutional policy, legal restrictions, and ethical issues, archivists may redact the information, destroy it, or limit access to it (either by user, or according to a certain period of time).
At the University of Cincinnati, we have a number of information security policies in place, including the Data Protection Policy (http://www.uc.edu/content/dam/uc/ucit/docs/itpolicies/9-1-1-B_DataClassificationAndDataTypes.pdf). This policy defines the difference between restricted and controlled data. Restricted data includes information such as social security numbers, credit card data, etc.
One tool that a lot of digital archivists use (and is packaged with Archivematica [https://wiki.archivematica.org/Release_1.5] and BitCurator [http://wiki.bitcurator.net/index.php?title=Software], two very popular suites of open-source tools to process and work with born-digital archives) is Bulk Extractor. Bulk Extractor uses a combination of pattern-recognition filters (for example, it will look for [text]@[text].[text] to flag email addresses). You can also set up a customized list of keywords you want to flag. Bulk Extractor is available for download here: http://digitalcorpora.org/downloads/bulk_extractor/
Depending on the types of filters you choose to run, Bulk Extractor spits out a series of reports after you execute it across a set of files. If a report is empty, it means it did not detect anything sensitive.
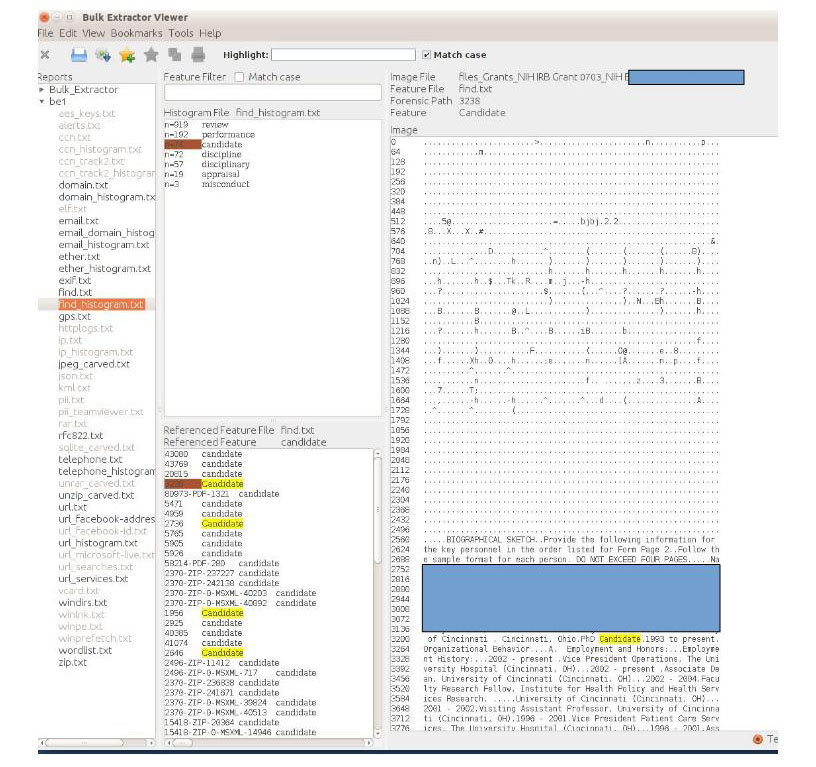
On the other hand, if it does pick up a keyword, you can then review it to ensure that it’s not a false-positive. Unfortunately I haven’t yet figured out a way to automate this step. Here’s an example using some keywords – also these may indicate personnel files, when reviewed in context, this particular example shows the word is in the context of a grant application.
Digital archivists are particularly attuned to the challenges of dealing with sensitive information, and this topic remains an important one within the archival community. This is an area where we could use some more tools that can specifically address the needs of the archival community with identification and redaction or removal of sensitive information – one such example so far is BitCurator Access (https://github.com/bitcurator/bca-redtools). Hopefully more will be in development as time goes on.
The Archives and Rare Books Library is located on the 8th floor of Blegen Library. We are open Monday through Friday, 8:00 am-5:00 pm. You can also call us at 513.556.1959, email us at archives@ucmail.uc.edu, visit us on the web at. http://www.libraries.uc.edu/arb.html, or have a look at our Facebook page, https://www.facebook.com/ArchivesRareBooksLibraryUniversityOfCincinnati.