
At the Archives and Rare Books Library, we recently began using Archive-It to preserve important university websites. The average life span of a webpage is between 44 and 100 days. Web pages are notoriously fragile documents, and many of the web resources we take for granted are at risk of disappearing.
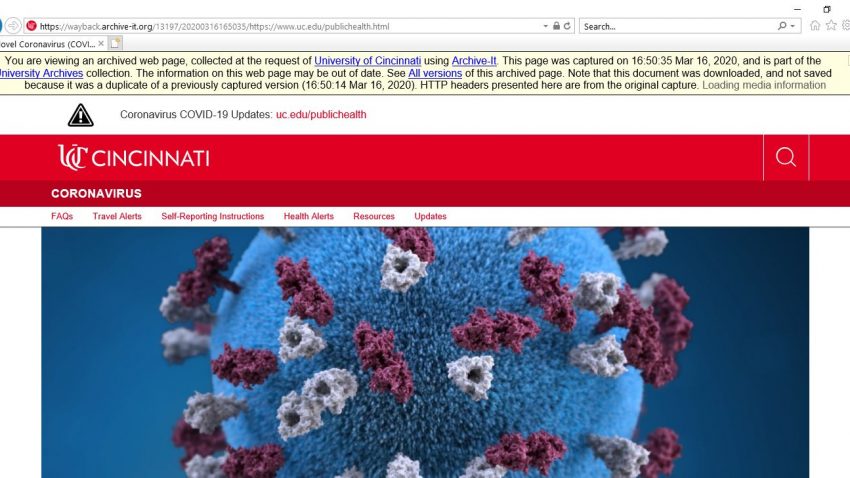
As the COVID-19 pandemic unfolds, we are using Archive-It to capture various UC domain webpages dedicated to the pandemic’s impact on the university community. This kind of rapid response web archiving will ensure we preserve a historical record of this monumental event at UC for future researchers. You can currently view the UC COVID-19 website archive, which is being updated on a daily basis.
So far, we have collected several gigabytes of data, and over 20 websites, including each college’s COVID-19 page. Since some pages update more frequently than other, we schedule crawls (i.e. the process of archiving a webpage) of pages like https://www.uc.edu/publichealth.html on a more frequent basis in order to capture all of the changes.
The Archives and Rare Books Library is not the only archival repository documenting the experience of COVID-19. Dozens of other institutions, including many other Ohio college and university archives, are also collecting and preserving this fast-moving event. One of the largest COVID-19 collections so far is a collaboration between the International Internet Preservation Consortium and Archive-It, which has now collected more than 2,763 websites in 30 languages about the worldwide response to the pandemic.
There has been growing interest over the last several years in developing ethical frameworks around documenting crises within the archives profession. In response, the Society of American Archivists created a Tragedy Response Initiative Task Force that has developed a comprehensive set of guidelines based on archivists’ professional ethics and values. Previous examples of online archiving projects of crises and traumatic events include the September 11 Digital Archive, Hurricane Katrina Digital Memory Bank, and Documenting Ferguson. Given the global reach of COVID-19 and the advances in web archiving and digital projects, the pandemic is likely to become one of the most well-documented global events in recent history.
Would you like to suggest a website that we should include in our COVID-19 UC web archive? Please email us to suggest new UC sites to preserve in our COVID-19 web archives. Please note that at this time, we are currently only crawling public-facing webpages directly related to the UC community of students, faculty, staff, and alumni.
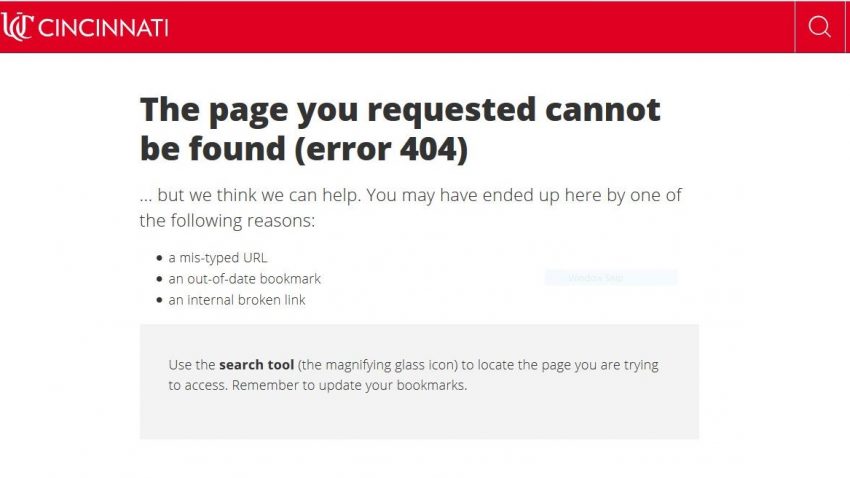 All of us have experienced clicking on a link and receiving an error, or
All of us have experienced clicking on a link and receiving an error, or